Method Overview
FlowPRO is a two-stage framework. Stage 1 performs supervised fine-tuning on a task-specific dataset to obtain a base policy from a flow-matching VLA backbone. Stage 2 then runs an iterative offline-RL loop on top of it for K rounds. In each round, three components work together:
- Intervention-and-Rollback Data Collection. A human operator teleoperates corrections only when the policy is about to fail, then rolls the robot back along the recorded trajectory and lets the policy retry. A single operator action produces a naturally paired trajectory (τw, τl), while the rollback horizon Δ diversifies the per-pair initial state.
- Smooth Interpolation. Sparse trajectory-level corrections are converted into dense per-state preference tuples by synthesizing the missing counterpart at each state via a smooth Bézier interpolation, preserving the base policy's local distribution.
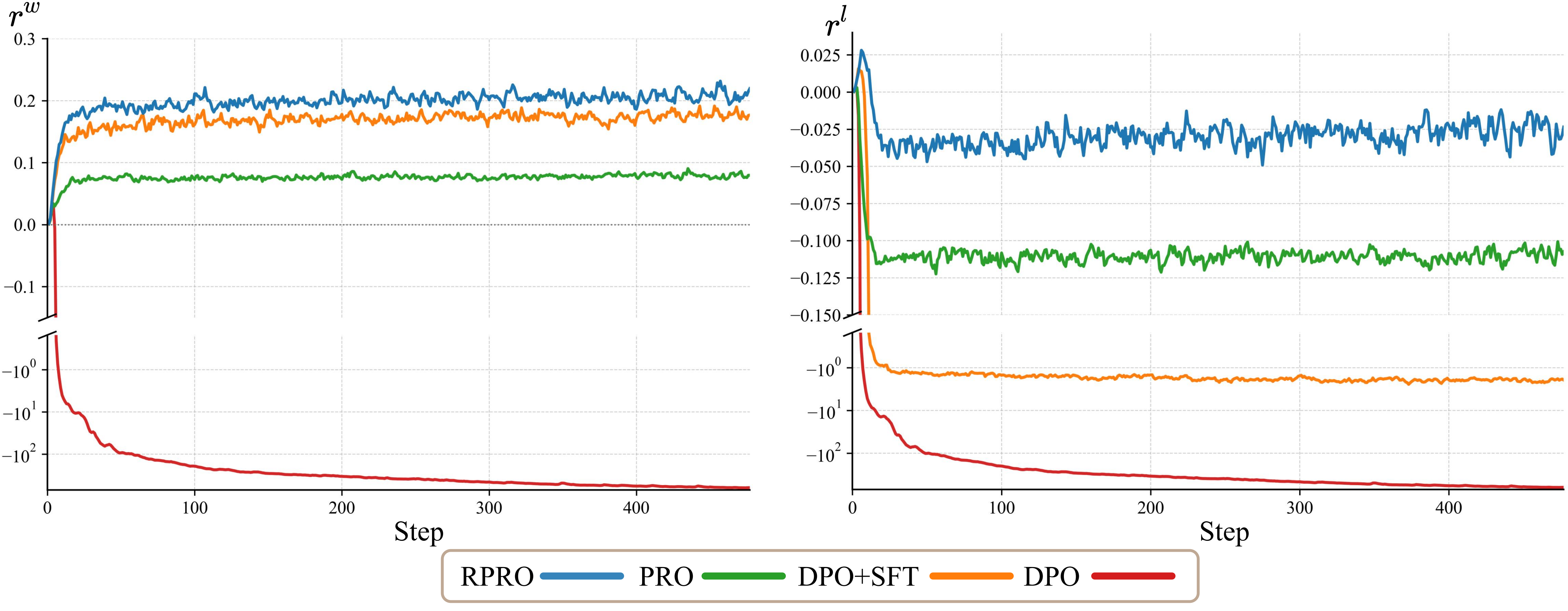
- RPRO Loss. The full RPRO objective combines a flow-matching adaptation of PRO with a supervised regression term: LRPRO = λPRO · LPRO + λSFT · LSFT. The proximal regularizer in LPRO anchors the absolute magnitude of the implicit reward at r ≈ 0, eliminating the reward-hacking failure mode of plain Flow-DPO. A gradient-vanishing property further makes preference pairs and SFT demonstrations compatible under a single loss.
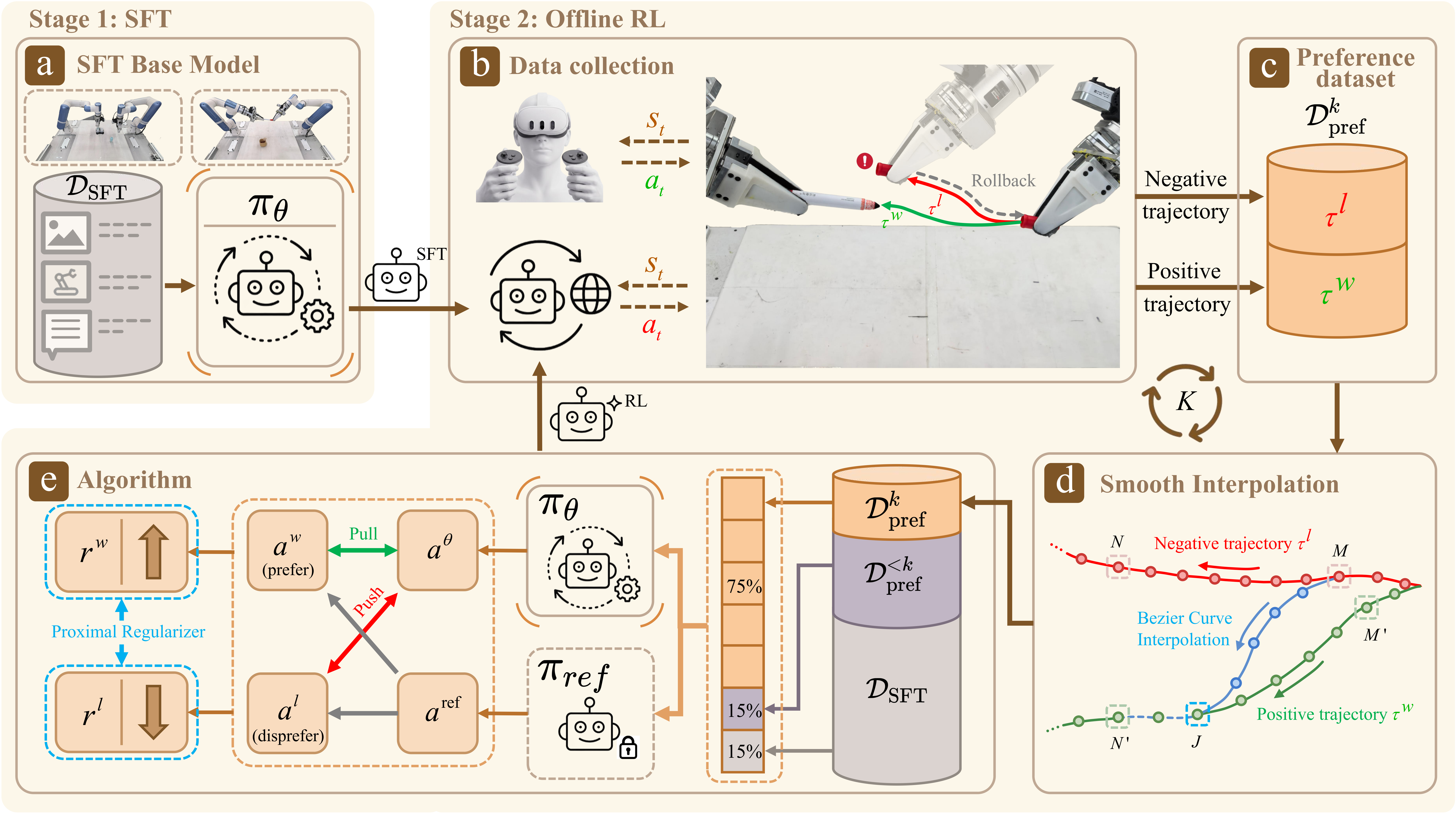
Figure 1. Overview of the FlowPRO framework. (a) SFT Base Model: Stage 1 trains πθ on DSFT. (b) Data Collection: operator-triggered rollback and operator teleoperation yield paired positive and negative trajectories (τw, τl). (c) Preference Dataset: pairs are aggregated into Dprefk. (d) Smooth Interpolation: Bézier interpolation synthesizes the missing counterpart at action-chunk granularity (e.g., M→J, J→N′), producing dense per-state tuples. (e) Algorithm (RPRO): aθ, aref from πθ and frozen πref are compared against aw/al to drive rw↑, rl↓, optimized on a mixed batch of Dprefk, Dpref<k, and DSFT; the updated policy is redeployed for K rounds.